Designing teams and distributed systems with DDD
I recently reread Domain Driven Design Distilled, a "concise" version of what was in the original 560 page book, Domain Driven Design (DDD). If I had to describe DDD in a single sentence:
The application of software design patterns at a system level, with a key agreement to use the concepts of domain experts within the codebases.
Patterns like OOP and SRP scale surprising well to multiple servers and applications. However, writing software using using the real-world names of the actors and processes has an even more profound effect on the architecture that is created. Closely related concepts can be grouped together into domains which teams can focus without fear of tripping over others. Services developed by these teams will have purposes that more closely mirror the actual tasks that users perform. This Ubiquitous Language isn't just used by engineers, but by all stakeholders. Product managers, marketers, business analysts, et al. will better understand the not only the function of the services that your teams deliver, but their value as well.
What was different for me on this read through is that I had just finished another book, Designing Data Intensive Applications (DDIA) by Martin Kleppmann. DDIA is wide ranging. It describes how to design distributed systems which can handle various different loads and access patterns. The author does this by first teaching all of the basic concepts of storage starting from file system, database internals and Unix pipes. Then he shows how to apply this knowledge to evaluate the tradeoffs of various technologies, like Map Reduce, in order to design network topologies for your specific use case.
I find that the ideas from DDD map very neatly on those of distributed systems. One example that I think illustrates this well is how Aggregates in DDD help you group together data should be committed synchronously. To put it another way, after you create an Aggregate, you will know which data needs to live together on the same physical machine (or that you will require fancy distributed transactions to commit). Conversely, you also can easily see what information can be transmitted asynchronously using an event system like Kafka (known as Domain Events in DDD).
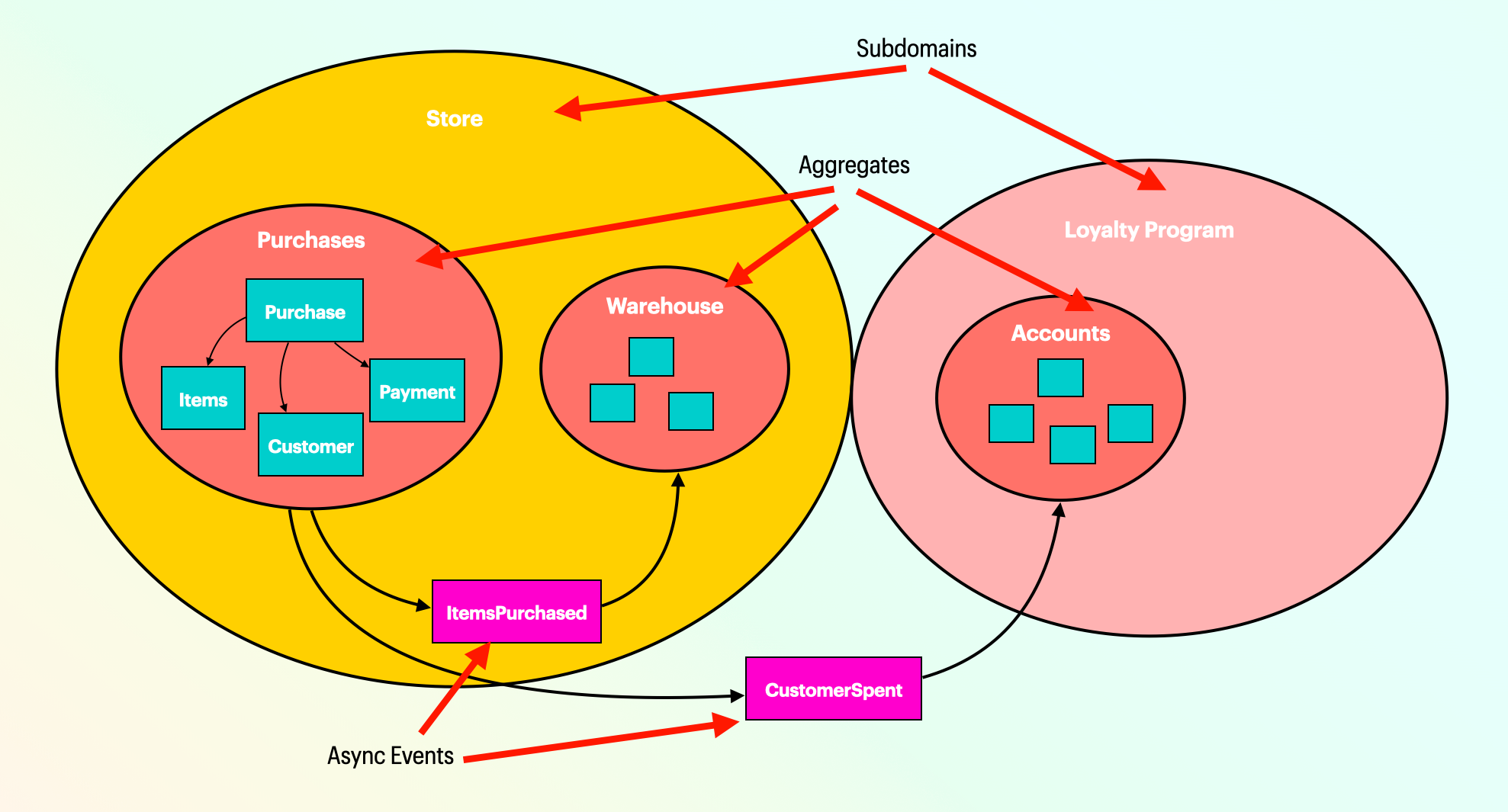
A domain model for a simple store application with a loyalty program
In the above example, you can see that it is important to the business that purchases process the payment immediately, but the warehouse inventory may not need to be updated until later, maybe each evening after closing. We also want to update their reward points after each purchase. The loyalty program does not need to otherwise understand language associated how payments processors or inventory management. That is why they exist in two different subdomains.
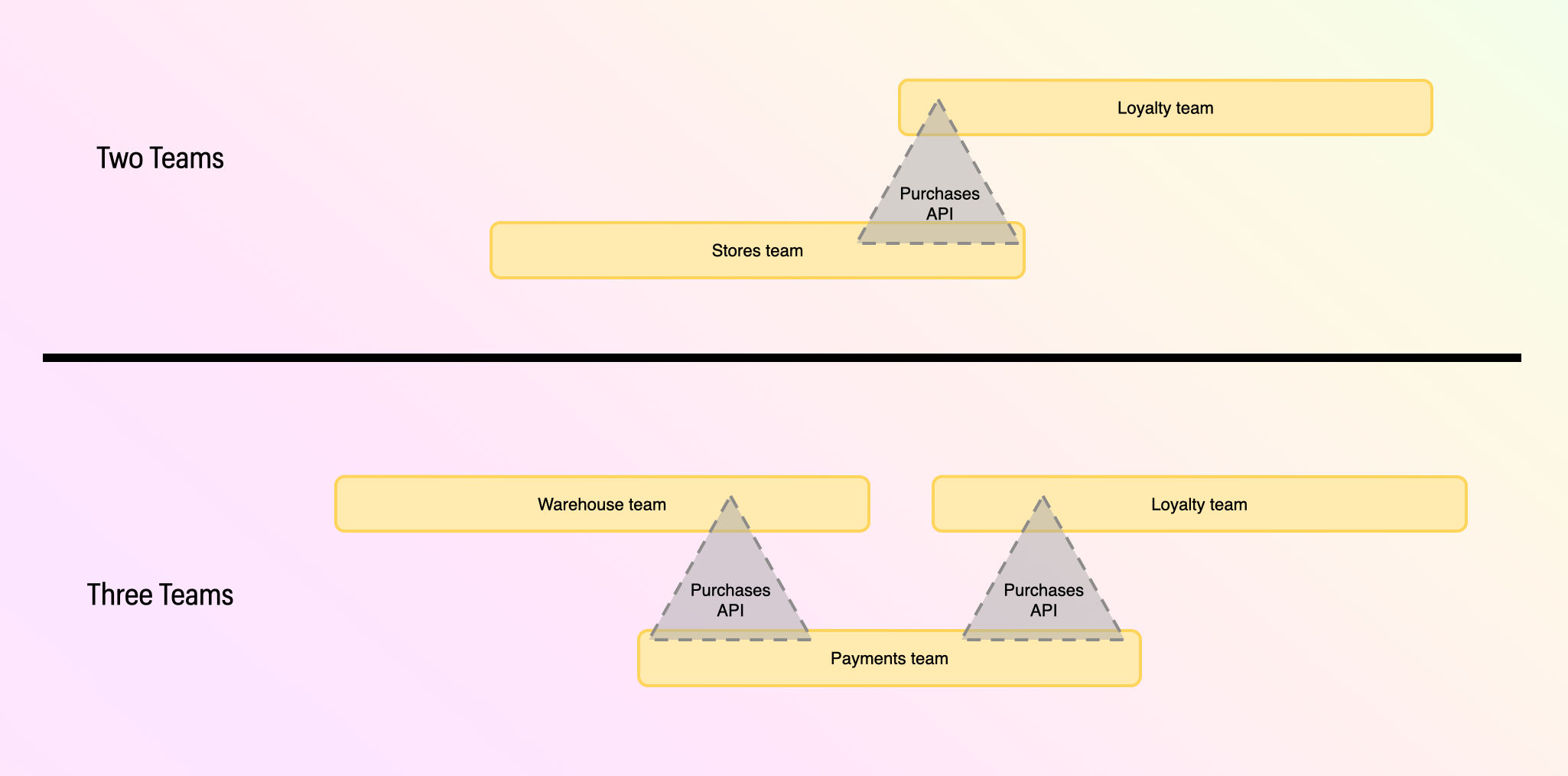
Designing your first teams to based on your domain design
These ideas also feed well into Organizational Design. Using a framework like Team Topologies, you can design teams based on the cognitive load of the systems they are developing and maintaining. One of the best ways in which can quantify that cognitive load is by defining Subdomains using DDD. A team ideally works in one Subdomain, but can handle a multiple depending on the complexity of each is small. And no subdomain should have multiple teams working in it. Teams should understand the language of their Subdomain deeply, but only need to know the APIs of other subdomains on which they depend. Teams should ideally develop APIs to fit the use cases of the consumers, rather than making others learn their internal domain language.
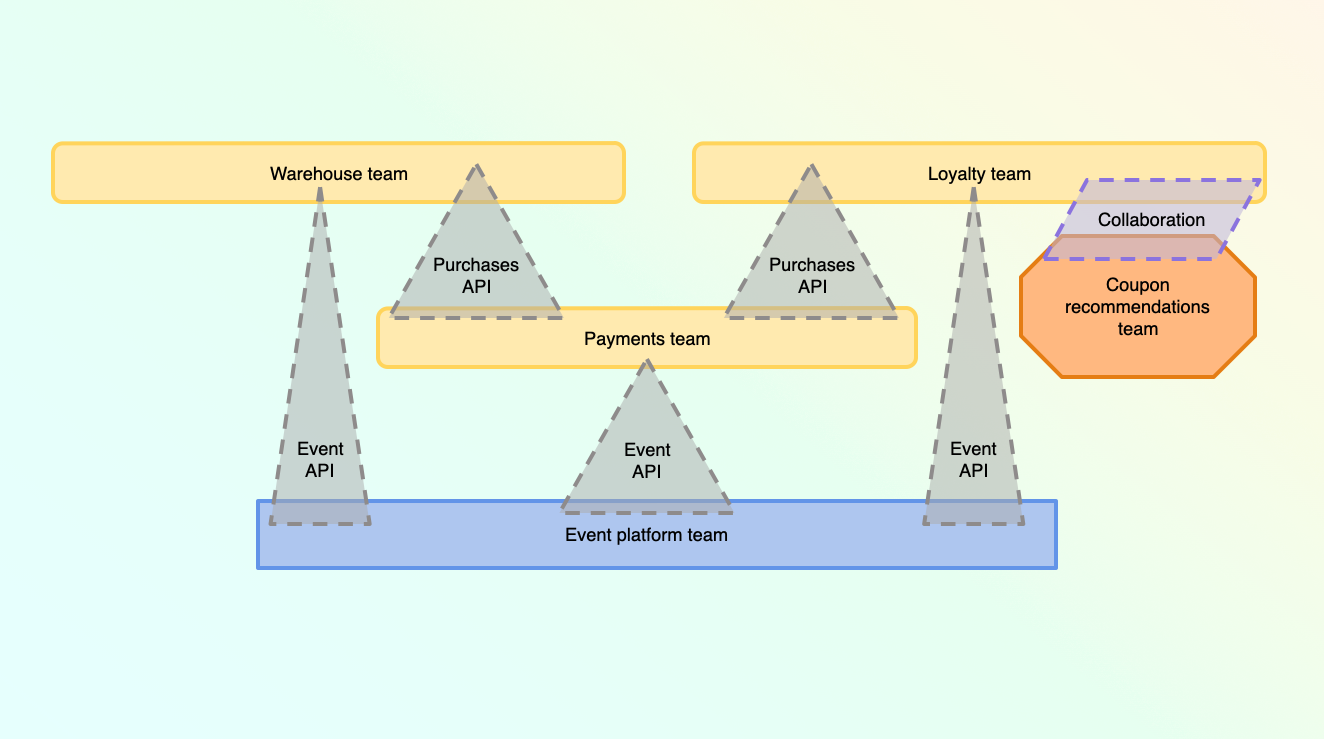
Adding more specialized teams as your organization grows
In our example you may first create just two teams, Stores and Loyalty, one for each subdomain. When you need to scale out, you have a natural way to split the Stores team into Payments and Warehouse giving you three teams. Your effort in separating the Aggregates of Payments and Warehouse, even when they were both maintained by a single team, makes it much easier to grow your teams when the time comes.
And as you continue to scale, you can add teams for more specific functionality, like one to maintain your event infrastructure, and another for developing machine learning capabilities for your loyalty program (Check out the Team Topologies website for more information on the design language I am using in these diagrams).
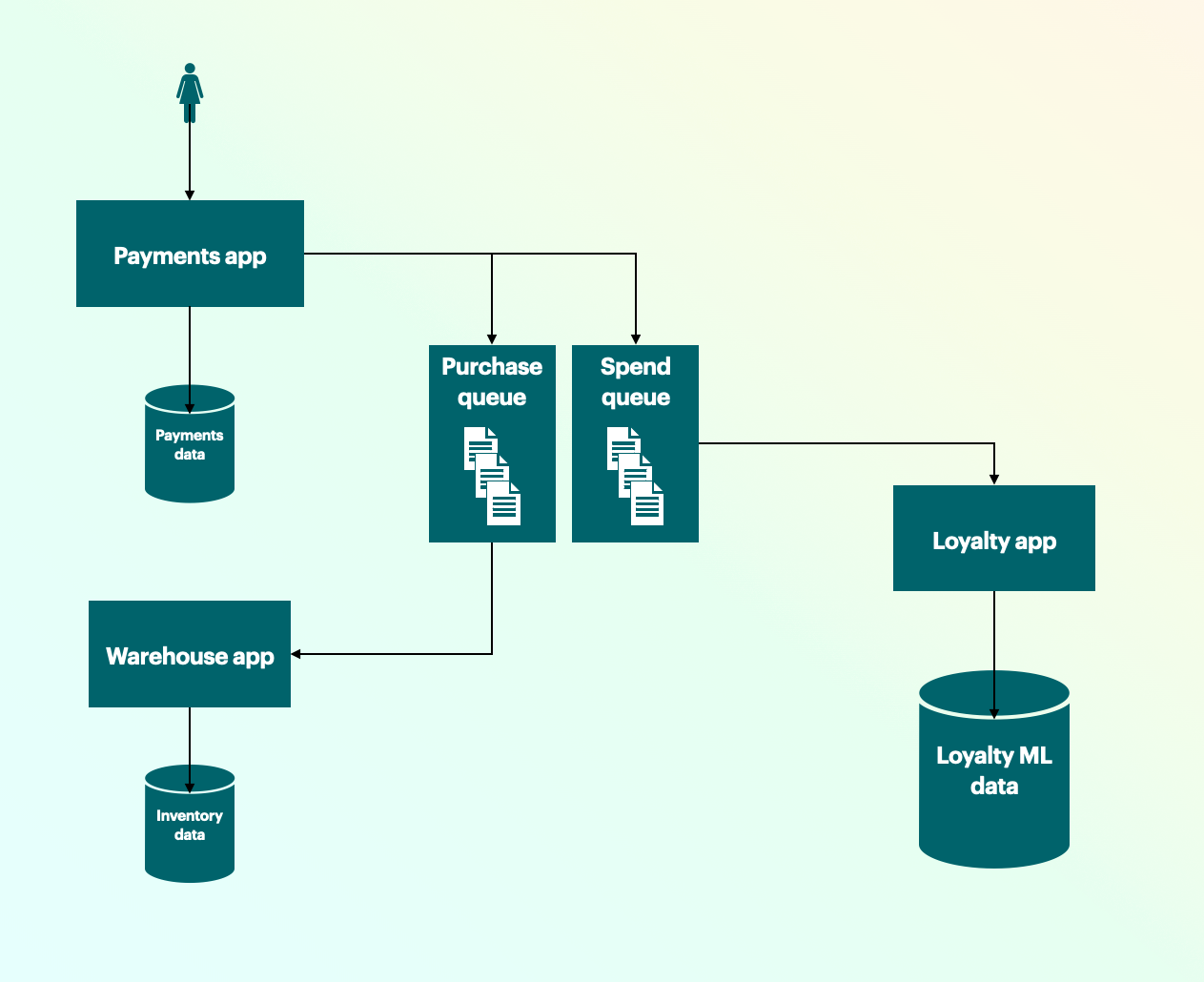
When those teams go to design (or redesign) their systems, their systems will begin to take the same shape as those teams based on the influence of Conway's Law.
By keeping the number of systems small in our example, I think it becomes very clear how each of these design systems mirror and reinforce each other. Their combined philosophies on language, people, and software help you design teams that create maintainable software, empowered teams, and a shared language that engages everyone. I think this is also why they work together so well as a toolset.
While this is was trivial design, these techniques scale to more complex systems and larger organizations. If you are growing your teams or planning a significant change to your product, adopting these patterns is a great way to bootstrap your Organizational Design process.